整体思路:
第一步:抓取所有的电子教材下载链接,输出到txt文本文件
book_list.py
Python
import requests
# https://s-file-1.ykt.cbern.com.cn/zxx/ndrs/resources/tch_material/version/data_version.json
urls = [
'https://s-file-2.ykt.cbern.com.cn/zxx/ndrs/resources/tch_material/part_100.json',
'https://s-file-2.ykt.cbern.com.cn/zxx/ndrs/resources/tch_material/part_101.json',
'https://s-file-2.ykt.cbern.com.cn/zxx/ndrs/resources/tch_material/part_102.json',
]
def book_list():
responses = [requests.get(url).json() for url in urls]
result = []
for response in responses:
result.extend(response)
file_contents = ''
for item in result:
if len(item['tag_paths']) <= 0:
continue
tags = [
next((tag['tag_name'] for tag in item['tag_list'] if tag['tag_id'] == id), '')
for id in item['tag_paths'][0].split('/')
]
directory = '/'.join(tags)
file_url = f"https://r2-ndr.ykt.cbern.com.cn/edu_product/esp/assets_document/{item['id']}.pkg/pdf.pdf"
output = f"out={directory}/{item['title']}.pdf".replace(' ', '')
file_contents += f"{file_url}n {output}n"
with open('book_list.txt', 'w', encoding='utf-8') as file:
file.write(file_contents)
if __name__ == '__main__':
book_list()
第二步:读取文本文件,开启多线程下载
book_download.py
Python
import os
import re
import requests
file_name = 'book_list.txt'
download_dir = './'
'''example
https://r2-ndr.ykt.cbern.com.cn/edu_product/esp/assets_document/bdc00134-465d-454b-a541-dcd0cec4d86e.pkg/pdf.pdf
out=教材/电子教材/小学/道德与法治/统编版/一年级/上册/义务教育教科书·道德与法治一年级上册.pdf
'''
def get_links(file_name):
with open(file_name, 'r', encoding='utf-8') as f:
data = f.read()
pattern = re.compile(r'(httpsS+)ns+out=([^n]+)')
matches = pattern.findall(data)
for match in matches:
yield match
def download(link, path, session=requests.Session()):
download_dir_name = os.path.join(download_dir, path)
if not os.path.exists((os.path.dirname(download_dir_name))):
os.makedirs(os.path.dirname(download_dir_name))
with session.get(link, stream=True) as r:
with open(download_dir_name, 'wb') as f:
r.raw.decode_content = True
downloaded_size = 0
for chunk in r.iter_content(chunk_size=1024 * 1024 * 1024):
f.write(chunk)
downloaded_size += len(chunk)
print(download_dir_name.split('/')[-1], downloaded_size, '/', r.headers['Content-Length'], end='r')
if __name__ == '__main__':
import threading
sub_threads = threading.Semaphore(8)
def download_thread(link, path):
sub_threads.acquire()
print('Download: ', path, link, end='n')
download(link, path)
sub_threads.release()
print('Done: ', path, end='n')
for link, path in get_links(file_name):
t = threading.Thread(target=download_thread, args=(link, path))
t.start()
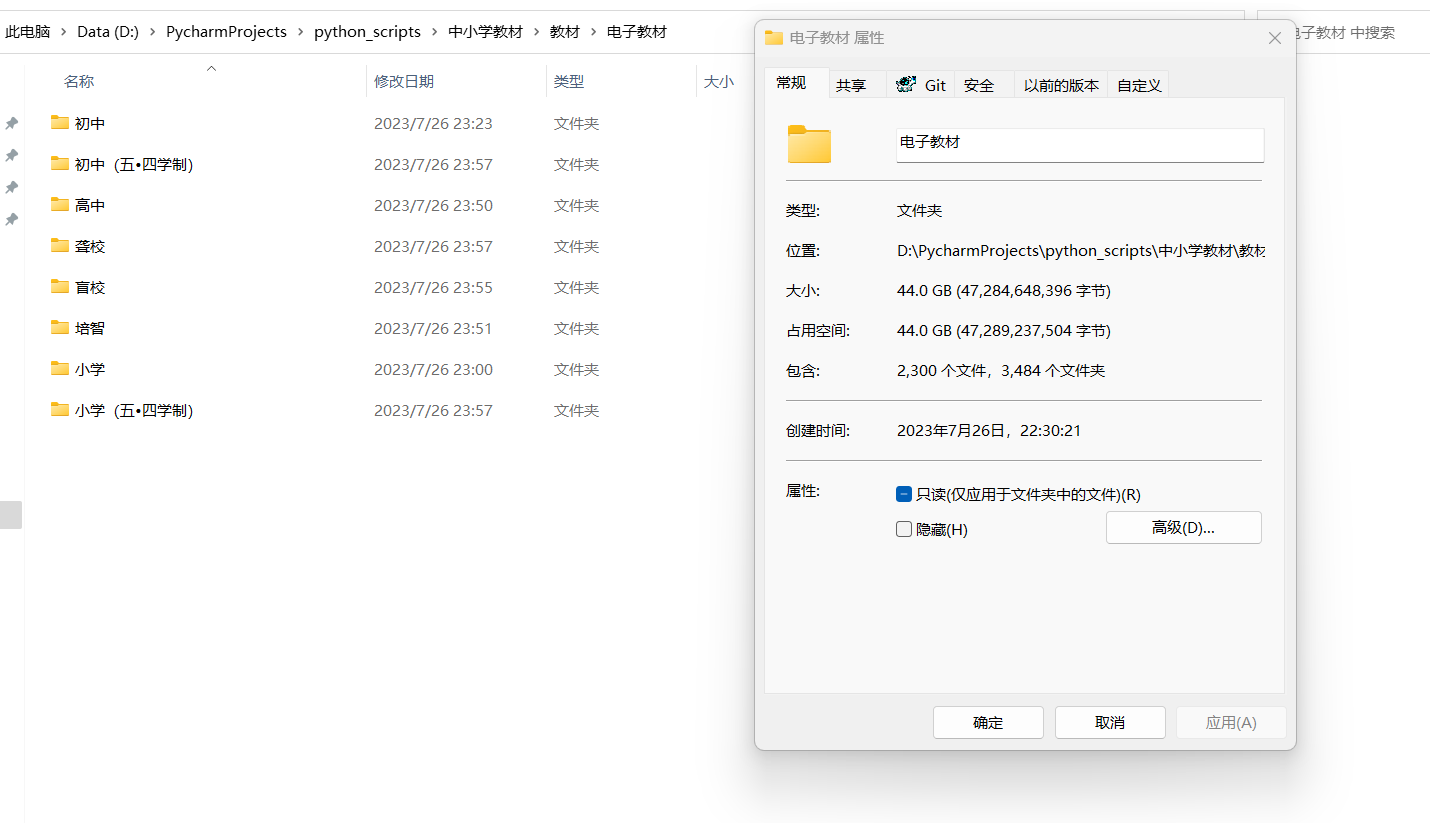
最后,下载完毕总大小44G,总文件数2300。
标签: 技术
您阅读本篇文章共花了:

发表评论